
这篇论文发表于2021年的S&P,一作 Nicholas Boucher 是剑桥大学的博士。这篇文章提出了一种针对NLP的新的攻击方式。此攻击通过对任务输入字符编码的修改,来让NLP服务的计算时间延长或者让服务给出错误的结果。它的一大特点就是经过攻击修改后的文字编码在经过渲染(比如浏览器、编辑器等)后,看起来和原本的文本是一样的(或基本差不多)。
背景及简介
近几年的研究表明,机器学习系统不论在理论上还是实际上,在面对敌对样本时都是比较脆弱的。在早些年,研究人员提出了对图像分类任务的一种攻击方式。在此攻击中,攻击者仅需要对图像进行极少量的修改(比如仅修改一个像素),就可以让模型给出一个不同的分类结果。后来研究者们又提出了一些针对自然语言文本的攻击方式。这些针对自然语言处理(NLP)任务的攻击存在的问题是:在这些攻击中,被修改后的文本无法保持原文本的语义或者无法确保不可区分性(indistinguishability)。
本文提出了一种新的针对NLP任务的攻击方式。它可以将NLP模型当作一个黑盒来处理并且攻击方式简单易实施,因此它可以覆盖大范围的NLP任务(包括线上已部署的大型NLP系统)。最重要的是,在此攻击中,被修改后的文本内容是无法从视觉效果上被区分开来,因此很难被发现。
攻击方式
NLP 任务基本工作流
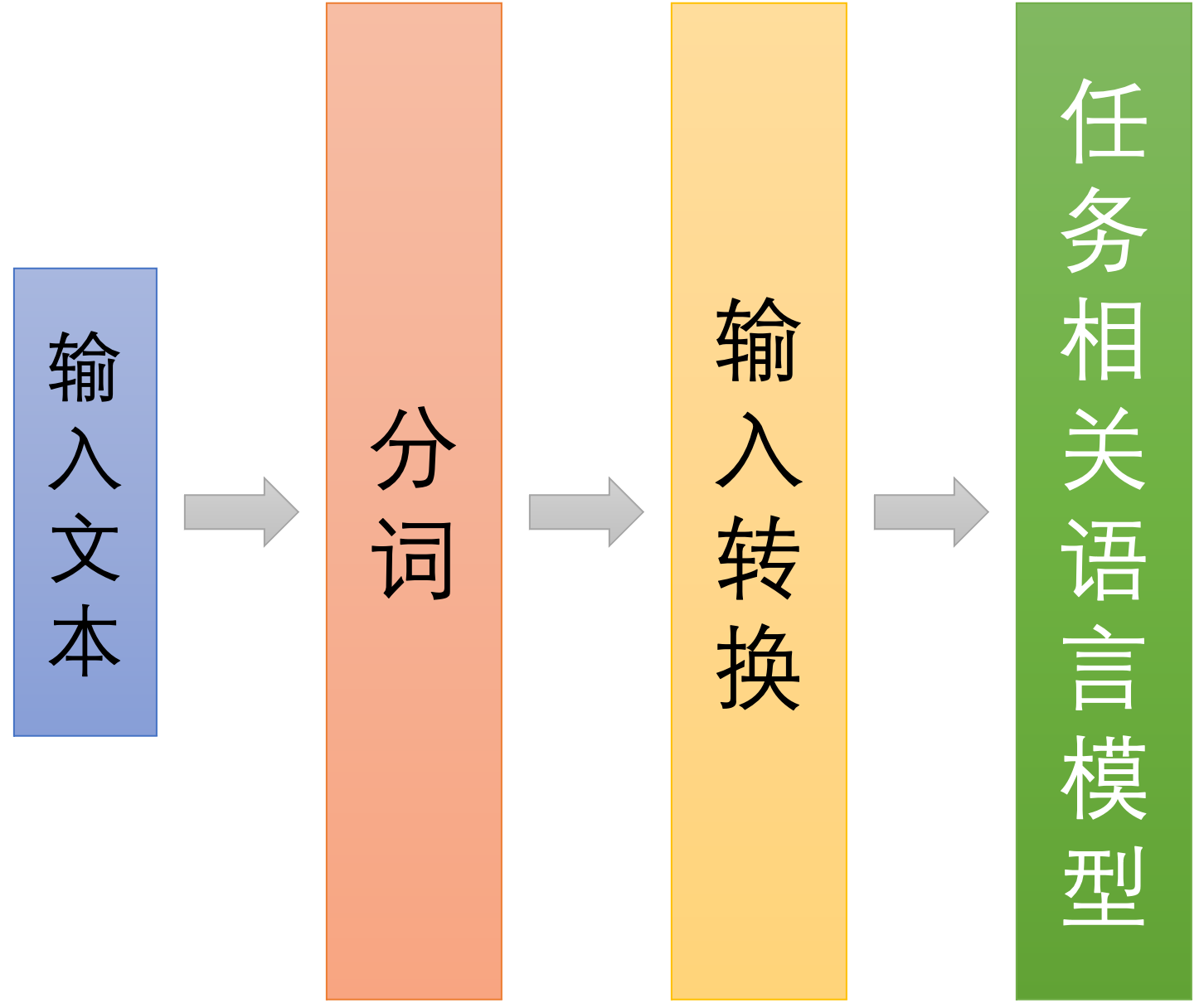
通常NLP语言模型无法直接处理文字信息,而是需要将其转化为神经网络可以识别的实数向量来处理。一般在NLP任务中,一段文本首先会经过预处理,而被转换成许多词,这些词可能是一个完整的单词,也可能是单词的一部分,这取决于分词的方式。典型情况下,这些词会被转换成其对应的词向量(经过输入转换)。最终得到的词向量序列被作为NLP任务相关模型的输入。
文字编码问题
我们知道,在计算机文件系统中存储的文本是以某种编码存在的。常见的编码比如utf-8/ascii,中文编码gb2312等。现行国际通用的编码为unicode编码,现行浏览器基本上都支持utf8编码。人们在查看文本文件时,应用程序会将字符编码转化为不同的字体来呈现给用户。
Unicode编码中包含了十几万字符,而在这些字符中,有一些字符对应的字形是十分相似,甚至是一模一样的。以ascii 编码来说,小写字母l与大写字母I看起来就非常相似。再比如两个字符rn连在一起,在很多sans serif字体中看起来就形似字母m。这种字形的相似性可以被攻击者利用。在2000年7月,攻击者利用域名paypaI.com(使用大写的I来伪装小写字母l)伪装成域名paypal.com来骗取用户的账号密码。再比如pаypаl.com看起来和paypal.com一模一样,实际上这两个的字符是不一样的,第一个域名中的а其实是Cyrillic字母,而不是英文字母a。大家可以将pаypаl.com复制到浏览器中看看浏览器显示的域名是什么。
此外unicode编码中,有很多字符是不会被显示的,大家可以复制这一串字符Ι loevу .uo,并使用搜索引擎搜索一下,你得到的结果一定不是I love you.相关的。这个字符串中包含了一堆不显示的字符,还包含了一些控制字符。或者可以试着将其使用翻译软件翻译一下看看结果。
词表覆盖率问题
在NLP任务中,特别是在实际应用的任务中,通常无法保证用户的输入是什么样子的。因此,语言模型在训练的时候应该尽可能覆盖更多的词。然而,出于模型大小以及实际性能等原因,将所有可能的词都包含在模型可以处理的词表中是不太现实的。所以,一些模型无法识别出来的词会被映射到一个特定的未知的词表示<unk>上面去。如果一个句子中被转化后,很多词被映射到<unk>上,那么显然该样本得到的处理结果应该不会很准确。这也是本文攻击路径利用点之一。
攻击途径
不可见字符

Unicode 编码中,不可见字符在显示的时候是不可见的,并且不会占用任何空白位置,比如:unicode中包含了一类零宽度空白符(zero-width space character, ZWSP)。
攻击者可以在NLP任务的输入文本中插入这些不可见字符(可以在单词之间或者单词内部插入不可见字符)来达到攻击效果,并且不容易被人发觉。
Note: 在一些字体中,一些不可见字符会被显示成某个特殊的字符,比如
。但是一般的字体会遵循utf编码标准,这些不可见字符不会被显示。因此,不可见字符被用来攻击是可行的。
相似字形

Unicode 中有很多字符在字形上是很相似的。Unicode 联盟发布过两个Unicode 安全机制报告。其中第一个定义了unicode中字行相似字符的映射。第二个文档中定义了可能会导致视觉上误会的相似字形的字符。
攻击者可以使用相似字形的字符进行替换来进行攻击。在本文的实验中,使用了unicode 的报告来作为相似字形字符的参考。实际上,如果我们没有相似字形的字符映射,我们也可以使用现有的卷积神经网络来对字形进行特征提取,然后进行聚类,来得到相似字形的字符。
重排序控制字符
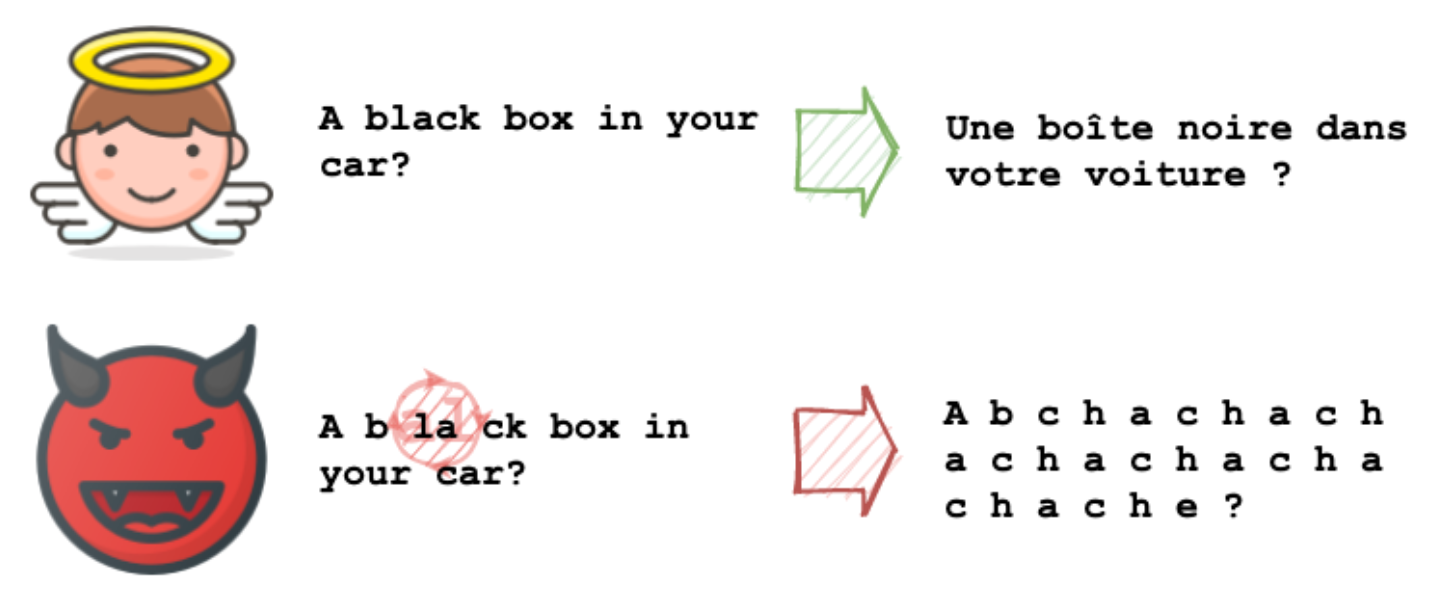
Unicode 标准中支持左->右和右->左两种阅读方式的语言。这两种阅读方式对字符的显示方式不同,那么到底如何显示呢?Unicode 规格标准中定义了双向算法(Bidirectional Algorithm, Bidi)来处理这个问题。实际上Bidi算法允许unicode 方向控制字符覆盖原先的字符显示方式,所以我们可以将文本进行任意重排列,然后使用重排序控制字符,让任意的重排列的字符串显示为原先的字符顺序。
这种重排列在显示的时候顺序是对的,但是机器在读取字符串时会顺序读取并编码,最终输入到NLP模型时就是一个完全无序的编码串,显然得到的输出也是无意义的。
删除字符

Unicode 中包含少量的控制字符可以将邻近的字符删除。最简单的比如:<return>(回车)字符CR,<backspace>字符BS以及<delete>字符DEL。举个例子:Hello <return>Goodbye World会被渲染为Goodbye World。
此种攻击方式在实际中是比较难应用的,因为用户是无法通过简单的复制/粘贴操作来复制这种删除字符的,复制的都是已经被处理完成删除字符后的结果。因此,此攻击路径只能通过手动注入的方式进行。
攻击目标
记NLP任务对应一个函数$f(x) = y: X \to Y$,输入一个文本$x\in X, y \in Y$,输出文本任务结果。记攻击函数为$p(x) = x^\prime: X \to X$,攻击函数输入一个文本$x \in X$,输出扰动后的文本$x^\prime \in X$。
文中提出两种攻击目标:
- 完整性攻击:攻击者希望找到一个函数$p$满足$f(p(x)) \ne f(x)$。如果攻击者希望NLP模型输出明确的目标$t$,那么攻击者同时还希望:$f(p(x)) = t$
- 可用性攻击:攻击者希望找到一个函数$p$满足$\text{ 耗时}(f(p(x))) \gt \text{耗时}(f(x))$,这里耗时指的是模型推理的耗时
扰动攻击数据生成算法
这篇论文里面的数据生成使用了差分进化(Differential Evolution, DE)算法。这个算法我也是第一次听说。最优化课程上居然没有讲过。去搜了一下DE的论文,巨佬的这篇论文已经有近3万的引用了。
DE算法详细内容可参考相关论文,这里简单介绍一下。DE算法对之前的遗传/进化算法进行了一些修改,但大致流程还是一样的。其中一个核心的修改点就是突变(mutation)的方法。传统的遗传算法中,我们一般会采用随机变异的方法。而在DE算法中,变异的方式不再是采取随机的方法而是使用差分的方法。举例来说,假设我们有$M$个随机人口(population)$p_1, p_2, \ldots, p_{M} \in \mathbb{R}^N$,每个都表示成一个$N$维的随机向量(与上文$p$含义不一样),那么传统的遗传算法中变异方式为:
$$
p^\prime_{ij} = p_{ij} + \epsilon \cdot \mathbb{1}_{selected}
$$
其中$p_{ij}$表示第$i$个向量的第$j$个元素,$\epsilon$表示服从特定分布的一个随机变量,$\mathbb{1}_{selected}$指示该值是否被选择来进行突变。而在DE算法中,突变方式为:
$$
p^\prime_{ij} = (p_{aj} + F * (p_{bj} - p_{cj})) \cdot \mathbb{1}_{selected}
$$
这里$a\ne b \ne c \ne i$,对于每一个$i$,DE会随机选取三个不同人口的下标,将其中两个$b, c$进行差值计算得到差值$diff$,而后此结果乘上一个因子$F$(一般$F \in (0, 2)$)被加到人口$a$上。当然$p^\prime_{i}$最终是否能够取代原有的$p_{i}$取决于新的人口的评分是否比原来的评分高,即:
$$
p_{i}^{new} = \begin{cases} p^\prime_{i}, & \text{如果 } score(p^\prime_i) \gt score(p_i)\\
p_i, & 否则
\end{cases}
$$
作者在论文中也没有说明为什么没有说明为什么使用DE算法,而没有使用传统的遗传算法,估计应该是也试过GA算法,但是效率没有DE好。关于DE的其它内容,比如为什么它有用、效率比较高,或者收敛等问题,大家可以参考相关文献,其实使用什么算法生成攻击数据不是本文的重点。
攻击预算
DE在此处应用时,作者设定了一个攻击预算常量$\beta = 5$用于控制变异的程度:$dist(p_i, p_i^{attack}) \le \beta$。其中距离衡量方式$dist$文中采用了Levenshtein 距离作为指标,也就是我们常说的编辑距离。
人口表示
在实现时,我们的人口$p_i$向量中的实数可以表示字符串的下标。以不可见字符攻击路径为例,$p_{ij}$可以表示我们期望在原始字符串中插入不可见字符的位置。Scipy的库中已经实现了相关算法,实际编码时直接调用即可。作者的代码已经开源,感兴趣可参考github上的代码。
攻击评价
对于完整性攻击,攻击对性能的影响可以直接使用原本NLP任务相关的性能进行衡量。对于可用性攻击,可以使用推理的时间长短进行衡量,耗时越长说明攻击效果越好。
实验结果
文中进行了大量的实验来验证攻击的表现,实验内容涵盖了:
- 机器翻译(直接测试模型+线上已经部署的服务)
- 敏感内容检测
- Textual Entailment(无目标+特定目标)
- 命名实体识别(无目标+特定目标)
- 情感分析(无目标+特定目标)
实验结果表明此类攻击在所有测试的NLP任务中均可成功,这里我们仅看一下英法翻译任务的部分结果。
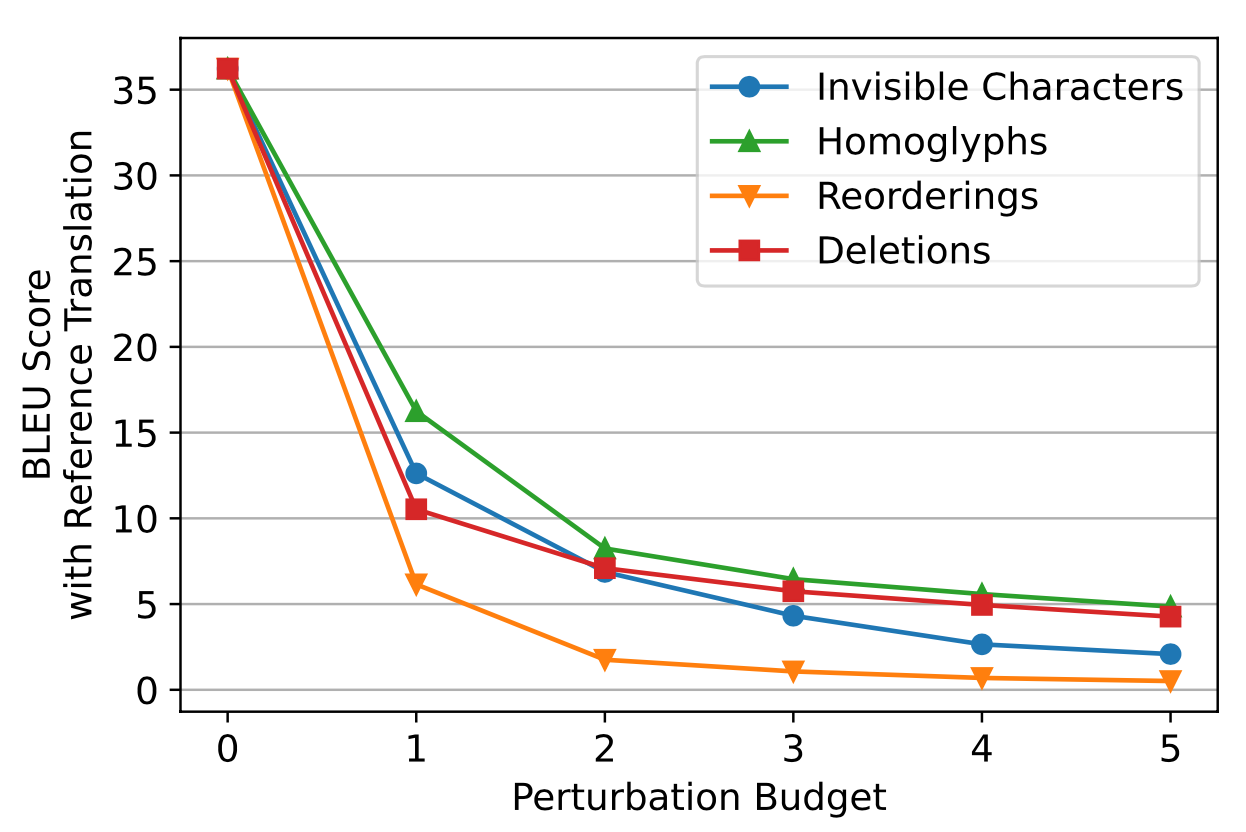
图中,横坐标为攻击预算,纵坐标为所得$BLEU$得分。可以看出所有攻击途径都可以极大降低翻译的性能表现。
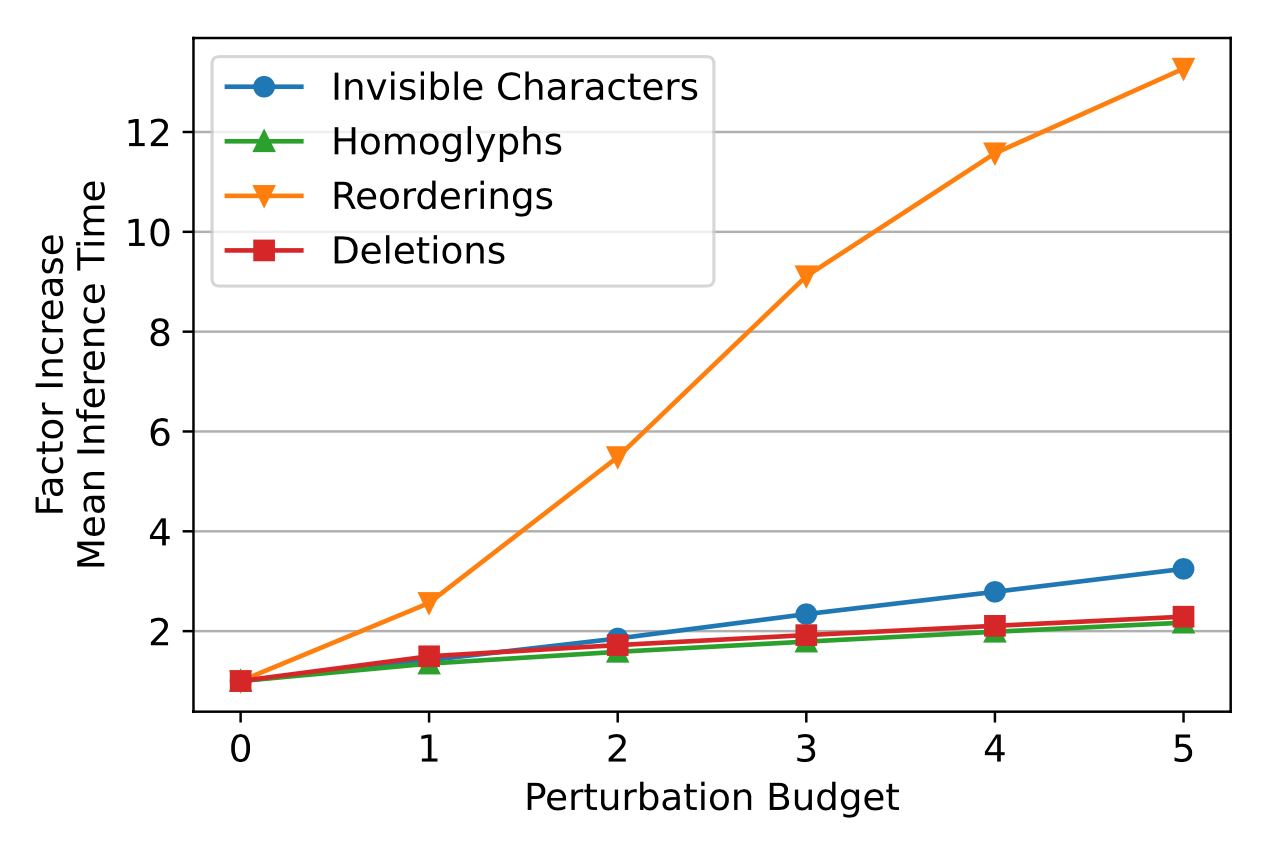
横坐标为攻击预算,纵坐标为推理时间。可以看出重排序可以极大提高推理时间。
前置阅读
这篇论文基本上是自包含的,很容易理解。对于差分进化算法,可以去看一下原论文[2],论文行文清晰明了(这篇论文应该是比较老的论文中非常容易理解的了)。
对于其它NLP相关的攻击,也可以随机挑选一下看看。
参考
[1] Boucher, Nicholas, et al. "Bad characters: Imperceptible nlp attacks."arXiv preprint arXiv:2106.09898(2021).
[2] Storn, Rainer, and Kenneth Price. "Differential evolution–a simple and efficient heuristic for global optimization over continuous spaces."Journal of global optimization11.4 (1997): 341-359.

更多推荐